In the former issues, we discovered the world formed by Hadoop, a world in which 100GB or 500GB files are something ordinary. This allows us to do things we weren"t able to do before.
The data our company collects can become a gold mine. As we are able to process huge amounts of data, we can visualize the data in a way that was not possible until now.
The first question we should ask when we wish to analyze the data with Hadoop is: What do we want to analyze? The answer to this question is important, because we need to clarify what we wish to do with the data, what information we wish to analyze and which is the value of this data.
A simple scenario is the identification of a user"s profile. We can thus recommend or advertise different products. Moreover, by using a system like Hadoop, we can create a mechanism for identifying frauds, by selecting the exceptions from the known patterns.

Compared to the rest of the solutions that are available on the market, Hadoop comes with extremely low costs. It does not require a special hardware on which to run. It can work without any problems on any kind of system, be it the laptop you have at home or the server from work in the 500.000 euro machine the client has purchased. Depending on the task we wish to perform, a job can take between a few minutes to hours or days. Hadoop has no restrictions from this point of view, being able to run for days, with no problems.
By simulating the environment in which it runs and the manner in which Hadoop is built, we are allowed to do something that cannot be done on any system of the kind. Scalability is linear. This means that if we double the number of nodes we can reduce to a half the analysis time. This way, we can start with a simple configuration and, if the data volume increases, we can increase the number of nodes.
Due to this feature, there are many cloud providers who offer this service. Any cloud provider can use the machines he has to run Hadoop and can scale the number of machines according to the client"s necessities.
A rather interesting story is that of Pete Warden who used Hadoop to analyze the profile of 220 milion Facebook users. This took only 11 hours and the cost was extremely low. Do you wonder how low? The final cost was 100 $. This is the perfect example where Hadoop works very well, on minimum costs.
As we have seen so far, the Hadoop architecture is simple, being based on HDFS - Hadoop Distributed File System and Map Reduce.
HDFS is able to divide, distribute and manage very large amounts of data. All this data, once stored in Hadoop, can be processed using MapReduce. The moment when the data is being processed, Hadoop does not send the data to the nodes that are responsible for processing it. Each data storing node in the system will process the data that it stores. Thus, data analysis is done much faster and the system is more scalable.
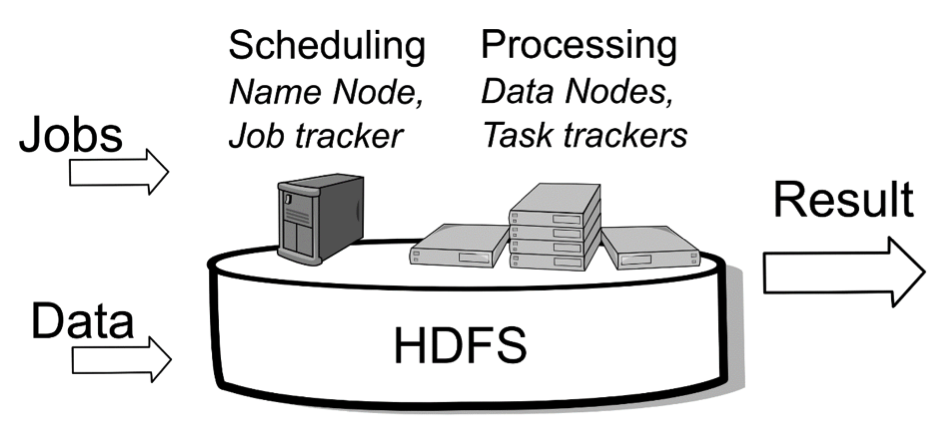
The MapReduce operation is an operation that unfolds in two phases. During the first phase, the Map operation runs on each separate node. The second analysis phase, called Reduce, is optional. The entire logic that we write - the manner in which we analyze data lays in the Map and Reduce operations.
The logic that we have to write in order to be able to write the analysis processes can be written in different languages. The thing we should not forget is that the language in which Hadoop was written is Java.
For this reason, even though we can use other languages besides Java, we will get the best performance by using Java. For example, if we use Streaming API, the performance may decrease by up to 20%.

If we wish to set up a Hadoop system, we must be ready to use Linux. Even though it has no problem running on Windows, initially Hadoop was designed to run on Linux. Linux knowledge will be useful to us the moment we have to set up this system. Under Linux, Hadoop runs on a Linux version derived from Ubuntu and RedHat. This is called CDH - Cloudera Distribution of Hadoop. A solution I recommend at this point is using some images that already have this system installed and set up. This way, in no more than 10 minutes we can have a functioning and ready to work system.
If we are at the development phase, then it is not recommended to run the code directly on a real system, since the debugging process can be extremely ticklish. In an initial phase, we can employ the Local Jobrunner Mode, which allows us to run small size tests and debug the Map and Reduce type operations. Once we have a functional code, we can move on to the next step and use Pseudo-Distributed Mode. This is a replica of the real environment, but offers us some debug functionalities. If we got beyond this step as well, then we can take the final step and go to the next, Fully-Distributed Mode. This is our real environment, that of production.
By developing and running the code in the three modes, the development cost decreases and the number of found bugs is high.
The programming style we have to apply the moment we use Hadoop is that of defensive type. We must try to figure out all the possible exceptions and treat them correspondingly. Running on several nodes, it is required that we treat each exception carefully.
In case you are not a developer and you do not know any programming language, it doesn"t mean that you cannot define your Map and Reduce operations. By using Pig and Hive, any person who has no programming knowledge can define their own rules.
Hive is based on a language called HiveQL. This is extremely similar to SQL. All that anyone has to do is to define a query of the kind:
SELECT * FROM CARS WHERE type = "BMW" AND value > 30000Hive will translate this query into jobs which Hadoop can execute.
Pig is fairly similar to Hive. It uses its own language called PigLatin. PigLatin is a simple language, with operations such as FOREACH, value comparing and SQL functions such as MAX, MIN, JOIN, etc. It translates the orders it gets into MapReduce type orders.
Both systems are easy to use and optimize. For those who are not developers, using Pig or Hive is a much better option than learning a language from scratch.
In the last three articles from this series we discovered the Hadoop world, how it can store and process such a big amount of data. All that is now left for us to do is to take the next step and start using it.
Good luck !
by Dan Suciu
by Radu Olaru
by Ovidiu Mățan







