These days, when it comes to huge popular websites, performance issues come up often along with the question: "How can we support such a huge userbase at a reasonable price ?". Facebook, one of the largest websites on the planet, seems to have a pretty good answer to this: the HipHop virtual machine. What is this, how was it born, how does it work and why is it better than the alternatives ?
I will try to answer all these questions in the following pages. The information presented here is scattered among many documents, interviews, blogs, wiki pages etc. In this article, I try to provide a big picture view over this product. Keep in mind that some features and functionalities will only be touched upon, not covered in depth, and that others will be omitted entirely. If you want detailed information about a feature of HHVM, please read the project"s documentation or its dedicated blog.
HipHop Virtual Machine (or HHVM) is a PHP execution engine. It was created by Facebook in the (successful) attempt to reduce the load on their webservers, which received more and more traffic as the number of users increased.
The history of HHVM starts in the summer of 2007 when Facebook started developing HPHPc. HPHPc worked in the following way:
In its glory days, HPHPc managed to overperform Zend PHP (the regular PHP platform) by up to 500 %.
These impressive results convinced Facebook"s engineers that HPHPc was worth keeping around. They decided to give it a brother: HPHPi (HipHop interpreted). HPHPi is the developer-friendly version of HPHPc and, besides eliminating the compilation step, it offers various tools for the programmers, among which is a code debugger called HPHPd, static code analysis, performance profiling and many more. The two products (HPHPc and HPHPi) were developed and maintained in parallel in order to keep them compatible.
The development of HPHPc took 2 years and, at the end of 2009, it ran on about 90 % of Facebook"s production servers. Performance was excellent, the load on the server dropped significantly (50 % in some cases) and everybody was happy. So, in February 2010, HPHPc"s source code was open-sourced and published on GitHub under the PHP License.
But Facebook"s engineers realized that superior performance wasn"t going to guarantee HPHPc"s success in the long run. Here"s why:
So, at the beginning of 2010 (right after HPHPc became open-source), Facebook put together a team that had to come up with a viable alternative to HPHPc, one that could be maintained for a long time. A stack-based virtual machine with a JIT compiler seemed to be the answer; the incarnation of this solution gave birth to HipHop Virtual Machine (HHVM).
At first, HHVM replaced only HPHPi and was used only for development while HPHPc remained on the production servers. But, at the end of 2012, HHVM exceeded the performance of HPHPc and therefore, in February 2013, all Facebook"s production servers were switched to HHVM.
HHVM"s general architecture is made up of two webservers, a translator, a JIT compiler and a garbage collector.
HHVM doesn"t run on any operating system. More specifically:
HHVM will only run on 64-bit operating systems. According to HHVM"s developers, support for 32-bit operating systems will never be added.

The big picture view on how HHVM works is:
Details about the steps listed above can be found in the following sections.
HHVM keeps the bytecode (HHBC) in a cache that is implemented as an SQLite database. When HHVM receives a request, it needs to determine which PHP file to execute. After the file has been identified, it will check the cache to see if it has the bytecode of that file and if that bytecode is up-to-date.
If the bytecode exists and is up-to-date, it will be executed. A bytecode that was executed at least once will be kept in RAM as well. If it doesn"t exist or if the file has been changed from the last time the bytecode was generated, then the PHP file will be recompiled, optimized and its new bytecode put in the cache. This procedure is basically identical to the way APC (Apache PHP cache) operates.
This behaviour also implies that, at a file"s first execution, there"s a significant warm-up period. The good news is that HHVM keeps the cache on disk, which means that, unlike APC"s cache, it will survive if HHVM or the physical webserver is restarted. So the warm-up period won"t have to be repeated.
Even so, the warm-up period can be completely bypassed. This can be done by doing a so called pre-analysis. This means that the cache can be pre-generated before starting HHVM. After installing HHVM, there will be an extra executable with the help of which the bytecode for the entire source code can be generated and added to the cache. This way, when HHVM starts, the cache is already full and ready to go.
Keep in mind that the cache keys also contain HHVM"s build ID. So, if you upgrade or downgrade HHVM, the contents of the cache will be lost and it will have to be re-generated.
An interesting way to run HHVM is the RepoAuthoritative mode. As I said in the section about cache, HHVM will check at each request if the PHP file changed since its last compilation. This translates to disk IO operations which, as we all know, are computationally expensive. They only take a fraction of a second, but it"s a fraction of a second that we don"t really have when we try to serve thousands of requests per minute.
When the RepoAuthoritative mode is activated, HHVM won"t check the PHP file anymore; instead, it will directly retrieve the bytecode from cache. The name of this mode comes from the fact that, in HHVM"s terminology, the cache is called a "repo" and that this "repo" becomes the authoritative source of the code.
The RepoAuthoritative mode can be activated by adding the following instruction in HHVM"s configuration file:
Repo {
Authoritative = true
}Some precaution must be taken with this mode because, if a file"s bytecode is missing from the cache, the client will get an HTTP 404 error, even though the PHP file is right there and can be executed without a problem.
The RepoAuthoritative mode is recommended for production servers for two reasons:
The bytecode is an intermediary form of code that is not specific to a specific CPU or platform, it is by definition portable. When executed, this bytecode is transformed to machine code in a process called Just-In-Time compilation (JIT). The compiler may transform only a piece of code, a function, a class or even an entire file.
Generally, there are three characteristics of JIT compilers that are important for their efficiency:
HHVM"s JIT compiler is its crown jewel, the module responsible for all its success. While the JIT compiler in Java"s virtual machine uses methods as basic compilation block, HHVM"s JIT compiler uses so called tracelets.
A tracelet is usually a loop because, according to research, most programs spend most of their time in a loop whose iterations are very similar and, therefore, have identical execution paths.
A tracelet is made up of three parts:
- type guard(s): prevents execution of input data of an incorrect type (e.g. an integer is expected, but a boolean is provided)
- body: the actual instructions
- linkage to subsequent tracelets
Each tracelet has great freedom as far as execution is concerned, but it needs to leave the virtual machine in a consistent state when the execution is finished.
A tracelet has only one execution path: instruction after instruction after instruction. There are no branches or control flow. This makes them easy to optimize.
In most modern languages, the programmer doesn›t have to do any memory management. Gone are the days when you had to deal with pointer arithmetic. The way a virtual machine (including HHVM) does memory management is called garbage collection.
Garbage collectors are split in two main categories:
Most garbage collectors are some sort of hybrid between the two approaches mentioned above, but one is always dominant.
Garbage collectors based on tracing are more efficient, have higher troughput and are easier to implement. This type of garbage collector was intended for HHVM but, as PHP requires a refcounting-based garbage collector, Facebook›s engineers were forced to temporarily drop the idea.
PHP needs a refcounting garbage collector because:
HHVM›s engineers really want to switch to a tracing-based garbage collector. They even tried it at some point; but, because of the restrictions mentioned above, the code got very complicated and somewhat slower, so they dropped it. Though there is a chance that this plan will be carried to completion in the following years.
One last point: HHVM has no cycle collector (object A references object B which references object A). There is one present in the source code, but it"s inactive.
HHVM works best when it knows a lot of static detail about the code before running it. Given that most of Facebook"s codebase is written in an object-oriented style, HHVM will deal best with that kind of code.
More specifically, it"s advised to avoid:
If possible, provide:
Also, it"s good to know that code in global scope will never be passed to the JIT compiler. This is because global variables can be changed from anywhere else. An example taken from HHVM"s blog:
class B {
public function __toString() {
$GLOBALS["a"] = "I am a string now";
}
}
$a = 5;
$b = new B();
echo $b;
The variables $a and $b are in global scope. When echo $b is called, the method __toString of the B class is called. This will change $a"s type from integer to string. If $a and $b would be JIT-ed, the compiler would become very confused about the type and content of $a.
Therefore, it"s best to put all the code in classes and functions.
As I said in the chapter about architecture, HHVM has two webservers. One of them is the webserver that serves regular HTTP traffic through port 80. The second one is called AdminServer and it provides access to some administrative operations.
To turn AdminServer on, just add the following lines in HHVM"s configuration file:
AdminServer {
Port = 9191
ThreadCount = 1
Password = mypasswordhaha
}The AdminServer can then be accessed at the following URL:
http://localhost:9191/check-health?auth=mypasswordhahaThe "check-health" option above is just one of many options supported by AdminServer. Other options allow viewing statistics about traffic, queries, memcache, CPU load, number of active threads and many more. You can even shut down the main webserver from here.
One of the most waited for features is the support for FastCGI. This was added in version 2.3.0 of HHVM (December 2013) and it"s a communication protocol supported by the most popular webservers like Apache or nginx. The support for this protocol means that there"s no need to use HHVM"s webserver anymore, but instead you can use for example Apache as webserver and let HHVM do what it does best: execute PHP code at lightning speed.
This feature is crucial because it will ensure HHVM"s popularity.

HHVM has experimental support for the extensions originally written for Zend PHP. This support is accomplished using a so called PHP Extension Compatibility Layer. The goal of this layer is to provide access to the same API and macros as PHP does, otherwise the extensions won"t work.
For a PHP extension to work, it needs to be recompiled using HHVM"s implementation of that particular API. Also, it must be compiled as C++, not C. This will usually result in some small but necessary changes to the extension"s source code.
HHVM also supports 3rd-party extensions, just like Zend PHP. They can be written in PHP or C++. The extension will then be added to HHVM"s source code and the entire HHVM will have to be recompiled. The new HHVM binary will contain the new extension and its functionality can then be accessed in the code that runs on HHVM.
HHVM already includes the most popular extensions like: MySQL, PDO, cURL, PHAR, XML, SimpleXML, JSON, memcache and many more. For now, the MySQLi extension is not included.
HHVM seems to be a solid, robust and fast product. But none of this would matter if HHVM wouldn"t be able to run real world code. HHVM"s engineers measure this ability by running on it the unit-tests of the 20 most popular PHP frameworks and applications like Symfony, phpBB, PHPUnit, Magento, CodeIgniter, phpMyAdmin and many more.
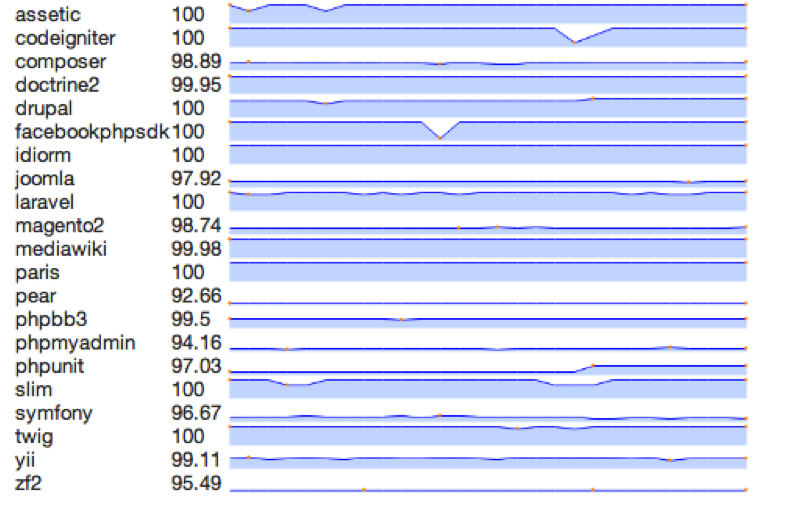
The numbers next to each application represent the percentage of unit-tests that pass for that application. HHVM"s engineers constantly improve these percentages on every release and they hope to reach 100 % on all of them in at most one year.
In the real world, the following websites are known to use HHVM:
Many of the sites that use HHVM will send a X-Powered-By: HPHP header as response.
In conclusion, HHVM is a revolutionary, robust, fast product that constantly evolves and, thanks to the support for FastCGI, it spreads rapidly. Many concepts and solutions used in HPHPc and HHVM have been reintroduced to Zend PHP. It›s the reason why there are so big performance improvements from PHP ٥.٢ to PHP ٥.٥.
by Ovidiu Mățan








