As previously discussed, in this paper, we run Klocwork Insight against Linux kernel (version 2.6.32.9) and we discuss the results of our analysis. Klocwork Insight version used for this analysis was 9.2.0.6223. Figure 3 shows the Klocwork checkers we have used for analyzing C/C++ source code. These are actually "checker families" or "categories" as each of these tree items (in figure 3) contains a number of individual checkers.
These checkers were enabled on Klocwork for our analysis to identify all significant issues in the source code being analyzed. The project metrics reported by Klocwork after analysis of the Linux kernel (2.6.32.9) code, are as shown in table.1.
TABLE I. PROJECT METRICS REPORTED FOR SCA OF LINUX KERNEL

In the following two sections, we discuss vulnerability analysis and complexity analysis of the Linux kernel after performing SCA on the Linux kernel code.
Certain Common Vulnerabilities and Exposures (CVE) identifiers for publicly-known information security vulnerabilities for numerous Linux kernel versions including version 2.6.32.9 are presented in table.2. The vulnerabilities listed in table.2 are not comprehensive by any means and are a subset of the vulnerabilities published in the National Vulnerability Database (NVD), after the release of the Linux kernel version 2.6.32.9. The release of Linux kernel version 2.6.32.9 was announced in February 2010. The vulnerabilities listed in table.2 were published in the NVD between February 2010 and July 2011, which is our sampling period. NVD is the U.S. government repository of standards based vulnerability management data represented using the Security Content Automation Protocol (SCAP). This data enables automation of vulnerability management, security measurement, and compliance. NVD includes databases of security checklists, security related software flaws, misconfigurations, product names, and impact metrics[13].
By performing SCA on the previously mentioned version of Linux kernel, we were able to identify the vulnerabilities shown in table.2. Further, these vulnerabilities that were identified using SCA account for about 10% of all the Linux kernel (v2.6.32.9) vulnerabilities reported between February 2010 (i.e., release of Linux kernel v2.6.32.9) and July 2011 (i.e., the end of our sampling period under consideration) in the NVD. Although, not all vulnerabilities published in the NVD that corresponded to the Linux kernel 2.6.32.9 could be detected by static analysis alone, the 10% issues that SCA was able to identify, as shown in table.2, include significant number of security and quality issues. Of this 10% vulnerabilities, about 22.3% were rated "High", 44.3 % were rated "Medium" and 33.3% were rated "Low" on the Common Vulnerability Scoring System (CVSS). This exercise successfully indicates that certain vulnerabilities (as shown in table.2) in the Linux kernel (includes version 2.6.32.9) published as recently as July 2011 in the NVD, could have been detected much earlier, had diligent static analysis and review of the kernel been performed earlier.
Another important factor to consider is the types of vulnerabilities that can be identified by SCA. The types of vulnerabilities that SCA was able to detect in our experiment include buffer overflows, integer overflows/underflows, integer signedness error and improper memory initialization. These are some of the vulnerabilities that have been frequently exploited to launch malicious attacks on various software applications. For example, buffer overflow anomalies have historically been exploited by computer worms like the Morris worm (1988) or the more recent Conficker worm (2008). It is well worth the effort to identify such bugs early on while incorporating opensource code along with proprietary code since our experiment demonstrates that SCA has the capability to detect a significant number of such bugs, and is a strong motivating factor to perform SCA on the adopted opensource code.
Beyond being able to detect these previously known vulnerabilities, the SCA tool was able to flag certain critical issues in the code, which may require further investigation to ascertain their genuineness and exploitability. Although the exploitability of some of these vulnerabilities cannot be justified by static analysis alone, it is well within the interests of any software vendor to address these issues before the software is released to the market. This establishes the value of performing SCA on opensource code to identify and fix certain coding issues early on, as opposed to waiting for the opensource community to identify and report these issues, since, sooner a vulnerability or bug can be detected the cheaper it is to fix.
TABLE II. LINUX KERNEL VULNERABILITIES DETECTED BY SCA
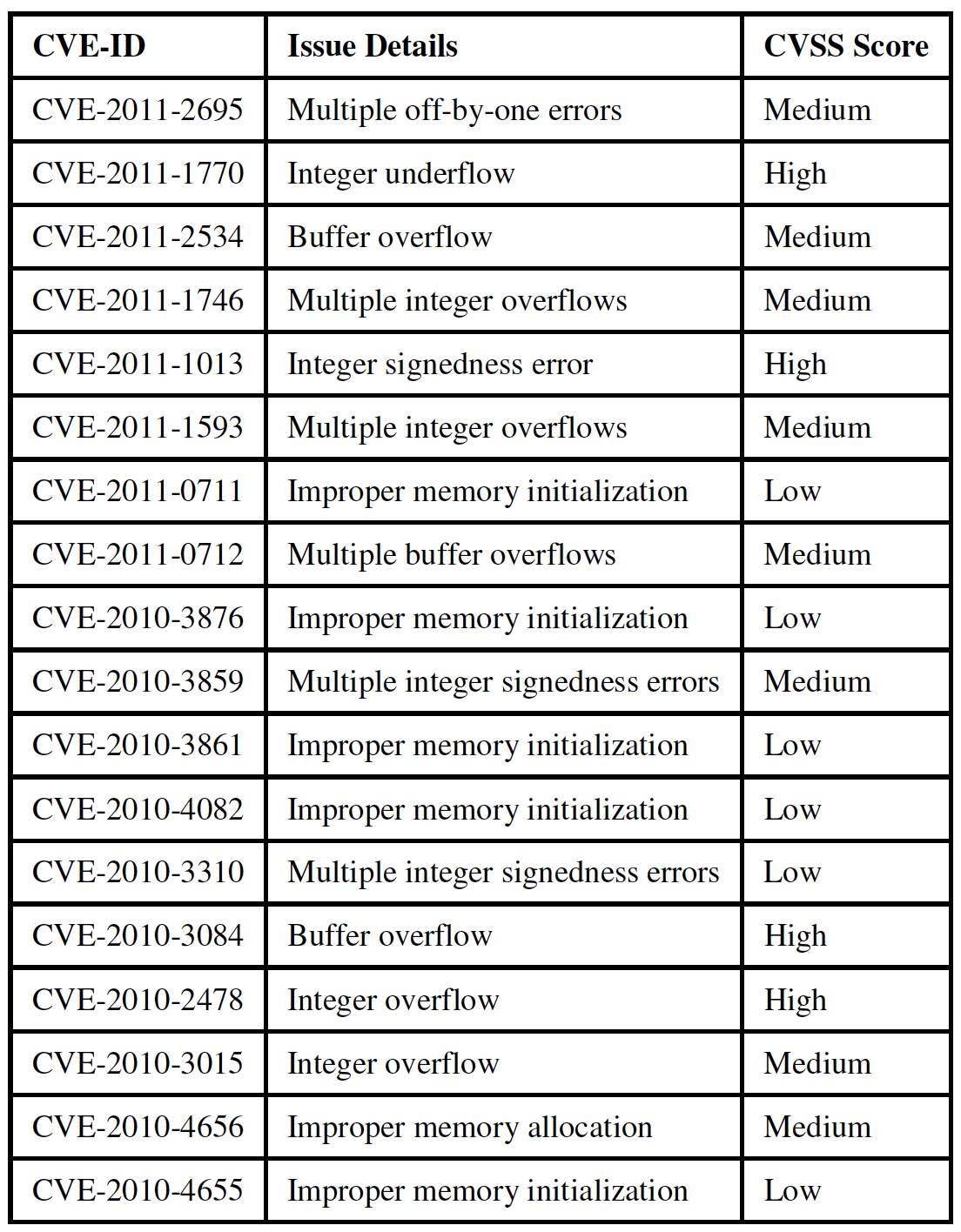
In order to analyze which components of the Linux kernel have higher incidences of vulnerabilities being reported, we break up the kernel files into six significant categories, which are as follows [12]:
A quick look through NVD shows that most of published vulnerabilities (years 2010 and 2011) for Linux kernel occur in "networking" components of the kernel, followed by "drivers" and "filesystems" components as seen in figure 4.
This can be attributed to the fact that the network stack, which, of course, deals with networking capabilities, is one of the most frequently, exploited components of the Linux kernel. This is consistent with the "attractive proposition" of launching remote attacks, and therefore, the network stack is a common target for exploitation which may account for the higher number of vulnerabilities being reported.

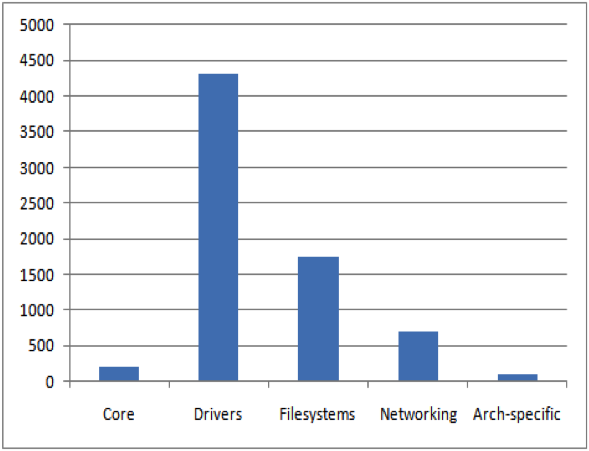
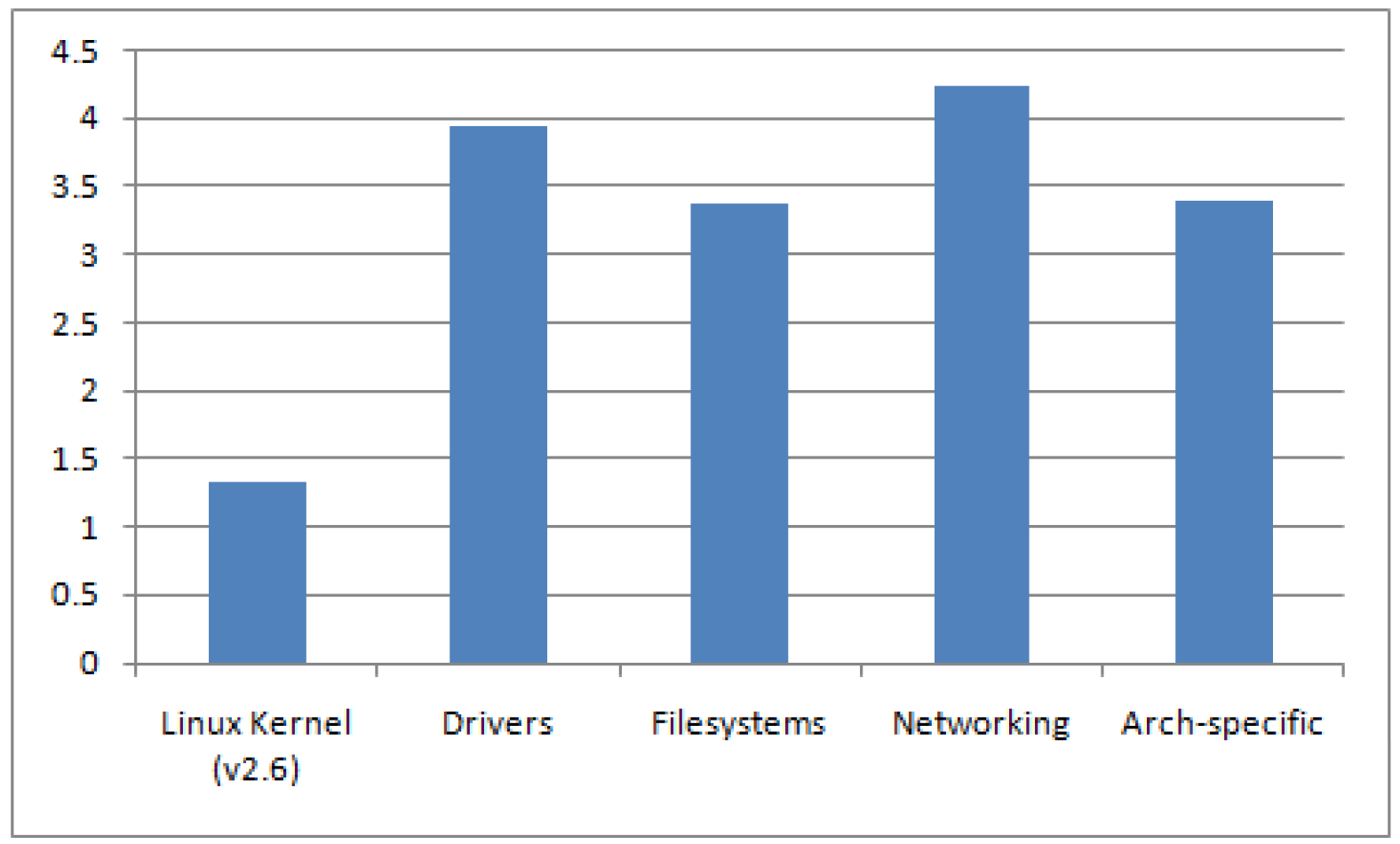
Usually, SCA tools can calculate the complexity metric for the programs that they analyze. In a nutshell, the complexity metric measures the number of decisions there are in a program i.e., it directly measures the number of linearly independent paths through a program"s source code. The more possible decisions made at runtime the more possible data paths. The National Institute of Standards and Technology (NIST) recommends that programmers should count the complexity of the modules they are developing, and split them into smaller modules whenever the cyclomatic complexity of the module exceeds 10, but in some circumstances it may be appropriate to relax the restriction and permit modules with a complexity as high as 15, if a written explanation of why the limit was exceeded is provided [9]. A high complexity metric makes it virtually impossible for a human coder to keep track of all the possible paths, hence when the code is modified or new code is added, it is highly probable that the coder will introduce a new bug. If the program"s cyclomatic complexity is greater than 50, such a program is considered as un-testable and a very high risk program. Studies show a correlation between a program"s cyclomatic complexity and its maintainability and testability, implying that with files of higher complexity there is a higher probability of errors when fixing, enhancing, or refactoring source code. In an opensource project similar to Linux, most of the development effort is communicated through mailing lists. The developers are spread across the globe and have varying levels of software development skills. Therefore, this situation may present a challenging task for any central entity responsible for coordinating the development efforts. The number of methods with complexity greater than 20 contained in the Linux kernel components are as shown in figure 5. The average complexity ratio (Maximum complexity of methods / Total number of methods) for methods with complexity greater than 20 per significant category in Linux kernel is depicted in figure 6. The first column in figure 6 represents the average complexity for the entire Linux kernel (v2.6.32.9) while the rest of the columns represent the average complexity for significant components contained in the Linux kernel. From figure 6, it is evident that the average complexity for the significant individual components in the Linux kernel is much higher (more than 2x) than the average complexity for the entire Linux kernel. A quick look through NVD shows that most of published vulnerabilities for Linux kernel occur in components containing a large number of higher complexity methods that mostly include "drivers", "filesystems", and "networking" components as shown in figure 4.
The percentage size per significant category in the Linux kernel (version 2.6) is shown in figure 7. The number of lines changed per significant category in the Linux kernel (version 2.6) is shown in figure 8. It is interesting to note that although, the "networking" component of the Linux kernel contains lesser number of higher complexity methods (from figure 5) and lesser Lines of Code (LOC) (from figure 7) as compared to "drivers" and "filesystems" components, a majority of the vulnerabilities published in the NVD occur in the "networking" component (from figure 4), the reason for which was discussed in the previous section on vulnerability analysis. Further, although the "networking" component of the Linux kernel contains lesser LOC, the average complexity (from figure 6) for the "networking" component is the highest when compared to other components of the Linux kernel, which suggests that higher complexity components tend to have higher number of bugs. Another interesting fact to note is that although the "architecturespecific" component of the Linux kernel has lesser number of higher complexity methods (from figure 5), it has higher
LOC (from figure 7), and it received significant number of LOC changes (from figure 8). Further, the average complexity (from figure 6) for the "architecture-specific" component is high, which suggests that components receiving higher number of LOC changes tend to have higher complexity.
In general, from our analysis, we observe the following patterns:
By observing these patterns, we may be able to concentrate the scope of SCA to these critical code components, which is explained in the following sections.
PROPOSED ALTERNATE WORKFLOW
As mentioned earlier and depicted in figure 1, opensource code incorporated in commercial software is usually not subjected to the same stringent static analysis and review as newly developed proprietary code. In the alternate workflow that we propose, as shown in figure 9, we recommend including SCA tool"s output for both newly developed software and adopted opensource software, in the formal software review package. This workflow will subject the opensource code to stringent code analysis and review process, along with newly developed proprietary code. Any software bug found by static analysis is fixed in both opensource and newly developed code before it is subjected to dynamic analysis and well before it is eventually released into the market. Of course, adhering to the license terms of the adopted opensource code is equally important and may require the communication of the fixes or code modification to the maintainers before the software is shipped. This process may not find all the bugs, but it will help catch certain bugs early on, providing an opportunity to fix these bugs earlier, as demonstrated in the previous section on vulnerability analysis. Further, consider the scenario of doing an upgrade of the open source components that have been incorporated. Adopting the proposed workflow will be even more helpful in such a scenario:
Although, static analysis of adopted opensource code is useful in identifying certain software bugs early on, there are technical and project oriented challenges that may not make this a viable proposition in certain situations as discussed further.
Although, SCA of adopted opensource code, along with newly developed code, is recommended, the challenges mentioned earlier, necessitate trade-offs due to budget, time and resource constraints that may seem necessary but probaby risky. Some ways of addressing the trade-offs are as follows:
Opensource software, Linux for example, is available to any entity seeking to acquire and use it in their products or projects, as long as they adhere to opensource software"s license terms. In our analysis, we have chosen Klocwork as the SCA tool and Linux kernel as codebase, only as examples or representative tools or projects, to highlight the issue of securing opensource code incorporated in commercial software. In general, our analysis can be extended to other SCA tools and other opensource projects. Although opensource projects define proper channels to report security and non-security bugs, these bugs are reported by individual developers as and when they come across them in an ad-hoc manner. Any unbiased dedicated effort to statically analyze the opensource codebase, document and report the findings is absent in the opensource community, although, of late, SCA companies like Klocwork or Coverity [10] have taken up the initiative in this direction. But even then, the rate at which newer versions of the opensource software gets released or updated, presents a barrier to such efforts. Efforts such as National Security Agency (NSA) Center for Assured Software (CAS) programs [11] which presented a study of static analysis tools for C/C++ and Java in the year 2010 using test cases available as Juliet Test Suites [14], is a step in the right direction, but even then, there are no absolute metrics for the choice of a particular SCA tool. Competing SCA vendors tend to find quite different issues in a common codebase, and the overlap becomes almost negligible by including as few as three different tools in the comparison. As a rule, not all issues identified by static analysis tools are by default bugs. A certain percentage of issues can likely be safely ignored after proper review. However, of the total set of found issues, a substantial portion does warrant correction. Although, a detailed further investigation is necessary to ascertain the exploitability of these bugs in runtime situations, for example by fuzzing [4] or by Directed Automated Random Testing (DART) [19], our analysis proves beyond any doubt that applying static analysis on opensource code has the benefit of catching certain critical bugs early on, as opposed to waiting for the opensource community to find and report these bugs, as and when they come across these issues. Identifying these bugs early on implies that these bugs can be fixed earlier. Software vendors incorporating GPL based opensource code in their proprietary software, may be required to make the entire project opensource including their proprietary code. Contrast this with incorporating Apache license or MPL terms based opensource code in their proprietary software, which does not bind the software vendor to make the entire project opensource. This may lead to a situation where part of the software is opensource and the rest is proprietary. Any exploitable bug found in the opensource part of this software can be virulent and the software product can be easily exploited without any effort spent on reverse engineering. Consequently, securing opensource code that is incorporated in commercial software is as critical as securing the proprietary software itself. Therefore, along with carefully validating newly developed proprietary software using SCA, it is also highly desirable to include static analysis of any opensource code necessary for the product, in the general software validation process and perform formal review of the needed opensource code before adopting it.
Analogy can be drawn to the build approach. When consuming an open source library, would the developer download a binary and include that directly in the build, or would the developer download the source and build it in the project milestones? By not consuming the binary directly and by downloading the source and building it in the project milestones, the project is protected from the vagaries of somebody else"s build environment that may not be relevant to the project. If so, why not include that same open source code in the static analysis run along with newly developed code? It is well understood in the software industry that the sooner a bug can be detected the cheaper it is to fix, thus avoiding expensive lawsuits or irreparable damage to company reputation. In many ways, this extra effort is critical in improving overall software product quality, reliability and security. Ultimately, organizations that can afford the cost and have a strong need will find value in this effort.
by Ovidiu Mățan







